

Ce projet a été réalisé dans le cadre du Datatalks data engineering zoomcamp pour valider ma certification.
Contexte & Objectif
Il avait pour vocation de m’entraîner à mettre en place un pipeline récupérant des données sur une ou plusieurs sources pour les envoyer dans un data-lake avant de les envoyer dans un data-warehouse sous forme plus raffinée et de finalement consommer ces données avec une EDA ou un dashboard.
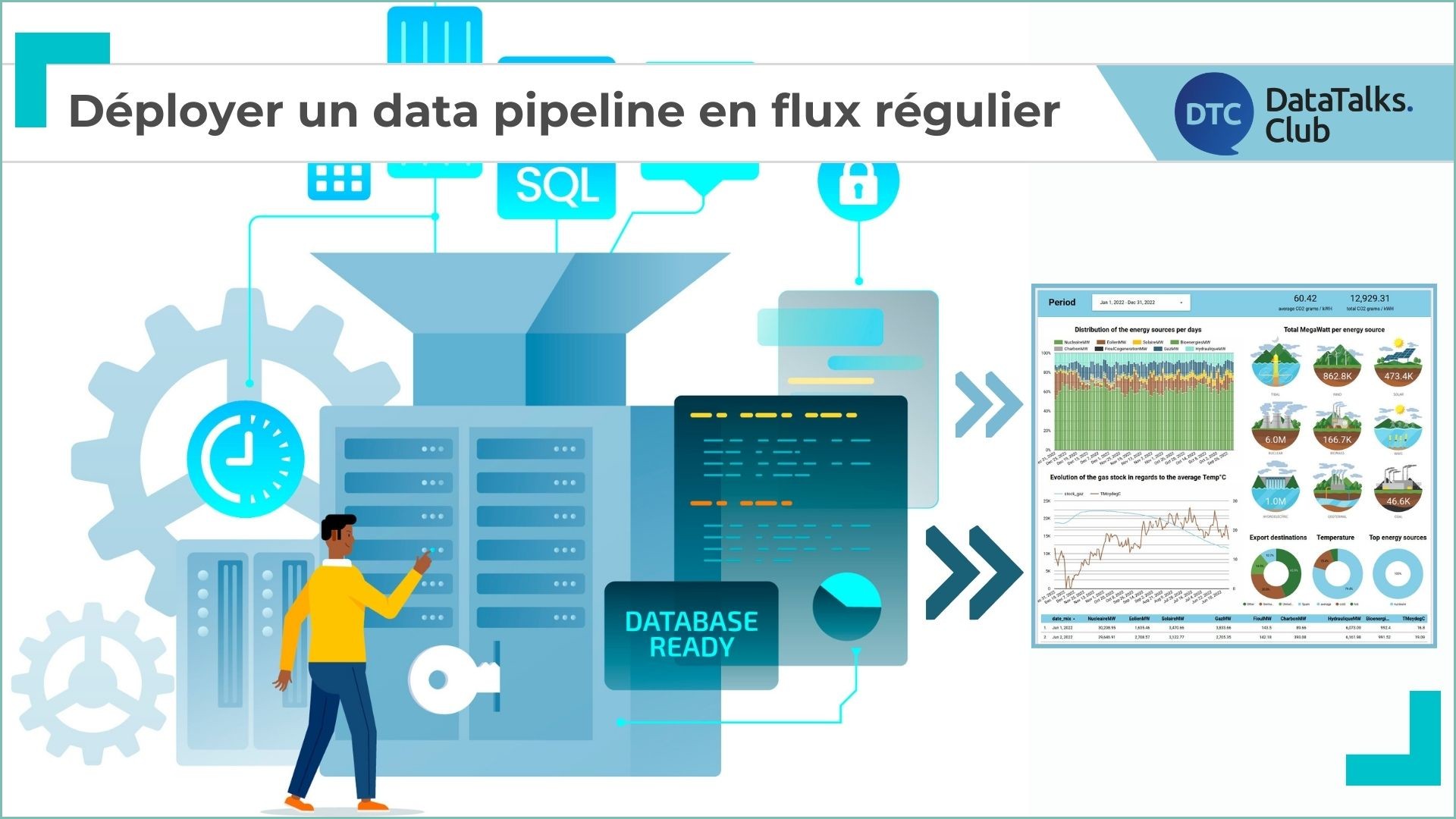
Mon pipeline se découpait donc comme suit:
Copie des données depuis les sites sources vers le data-lake(Google Cloud Storage dans ce cas)Copie des données du data-lake vers un data-warehouse(BigQuery dans ce cas)Transformer les staging-datapour produire des developement/production-data utile à notre projetConsommer les nouvelles donnéesvia un tableau de bord personnalisé and directement depuis BigQuery
Voici donc un schéma permettant de voir le cheminement des data dans le pipeline
Sources de données
Afin de mener à bien ce projet, j’ai sélectionné 3 jeux de données sur le site web ODRÉ (Open Data Réseaux Energies).
Ces jeux de données sont particulièrement intéressants pour moi car ils fournissent des données en direct qui proviennent directement des transporteurs d’énergie et de leurs partenaires et chacun est mis à jour avec une fréquence différente (toutes les 1 heures / tous les 1 jours / tous les 1 mois).
Source 01 : Données éCO2mix nationales temps réel
Ce jeu de données, rafraîchi une fois par heure, présente des données “temps réel” issues de l’application éCO2mix. Elles proviennent des télémesures des ouvrages, complétées par des forfaits et estimations.
Source 02 : Stock quotidien dans les stockages de gaz
Ce jeu de données présente le stock de gaz présent dans les stockages de gaz de Teréga et Storengy, par PITS et en fin de journée gazière depuis le 1er novembre 2010 (GWh PCS 0°C).
Source 03 : Température quotidienne régionale
Ce jeu de données présente les températures minimales, maximales et moyennes quotidiennes (en degré celsius), par région administrative française, du 1er janvier 2016 à aujourd’hui. Il est basé sur les mesures officielles du réseau de stations météorologiques françaises.
Je les ai donc choisis parce-qu’ils touchent à un sujet qui m’intéresse, mais aussi et surtout dans ce cas parce-qu’ils sont techniquement intéressants.
Avec un pipeline de ce genre, un data-scientist peut essayer d’extraire des informations intéressantes.
- Quelle est la répartition des sources d’énergie pour un jour donné ou une période donnée ?
- Le stock de gaz est-il corrélé d’une manière ou d’une autre à la température ?
- Les sources d’énergie sont-elles influencées par la température ?
- Les sources d’énergie sont-elles influencées par le stock de gaz actuel ?
- La répartition des sources d’énergie change-t-elle avec les saisons ?
- Y a-t-il plus d’échanges commerciaux liés à l’énergie lorsque le stock de gaz est plein aux frontières ?
Outils utilisés
Terraform : pour mettre en place facilement et rapidement les infrastructures nécessaires
Prefect : pour exécuter de façon automatisée des scripts python qui transfèrent les données
dbt : pour transformer les données et créer de nouvelles tables à partir des jeux de données originaux
Google Cloud Storage : pour le data-lake
Google BigQuery : pour le data-warehouse et l’exploration des données (attention à optimiser les requêtes!)
Google Looker Studio : pour la visualisation des données / le dashboard
Python : pour écrire les différents scripts Prefect
SQL : pour écrire les différents modèles dbt
Makefile : pour simplifier le processus de déploiement
GitHub
Le dépôt Git contient l’ensemble du code ainsi que des instructions très précises permettant de reproduire le projet.
Dépôt GitHub du projet
Dashboard
Le but étant de mettre en place le pipeline, je n’ai pas cherché à faire un dashboard très poussé, mais voici un aperçu du résultat:
Live dashbord (les données ne sont pas forcement à jours car je ne garde pas le pipeline toujours actif en raison des coûts des différents outils)